

- Proxies
-
- AI Scrapers
-
- Solutions
-
- Resources
-
-
Resources menu

-
-





















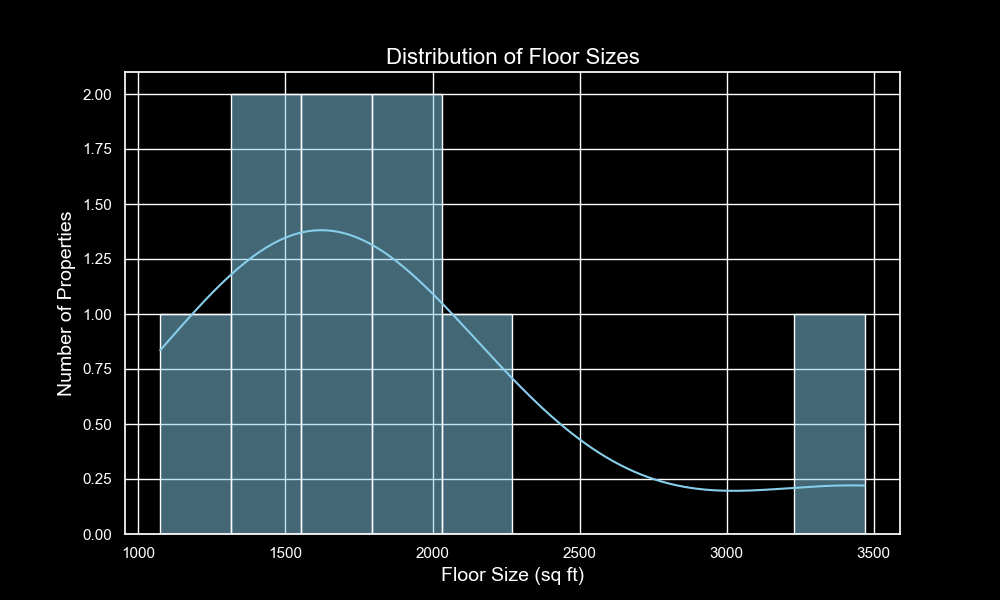
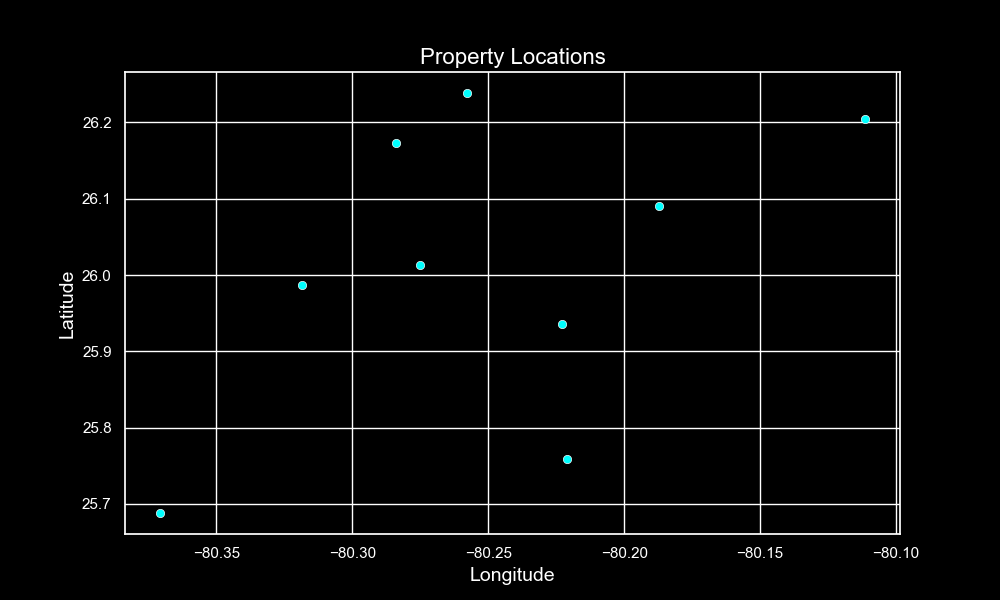
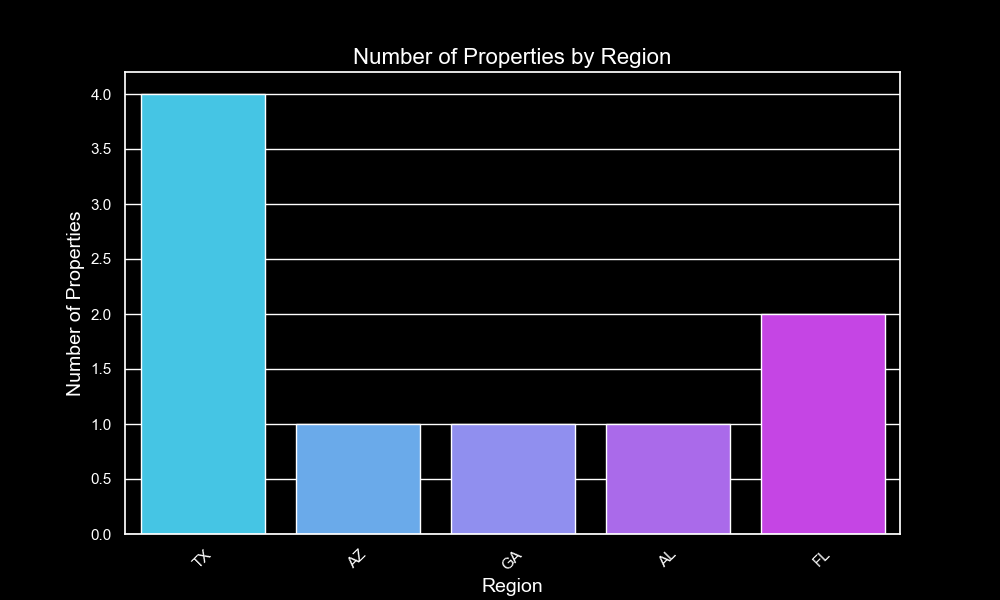
Let’s start out by building our custom scraper for Zillow. We’ll write it in Python because of its simple syntax, which is accessible to all. Feel free to implement your scraper in any language. We’ll explore the endpoints from which we can fetch data and parts of the website from which we can scrape valuable information. For this example, we’ll look at residential properties.
Head over to Zillow. Click “Buy”.
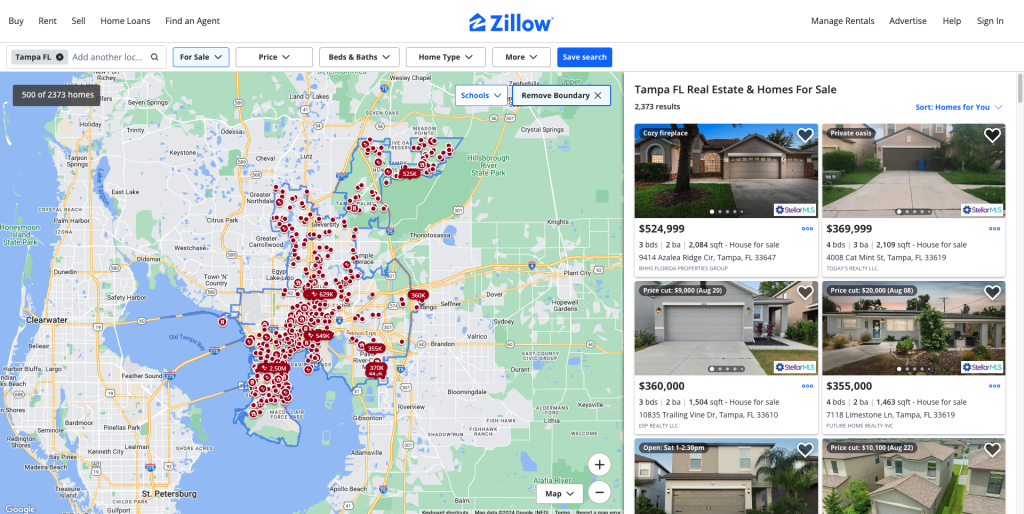
This is the endpoint where all property listings are made. We are interested in the cards in which properties are listed. They contain information like pricing, physical facts, and developer tools in your browser.
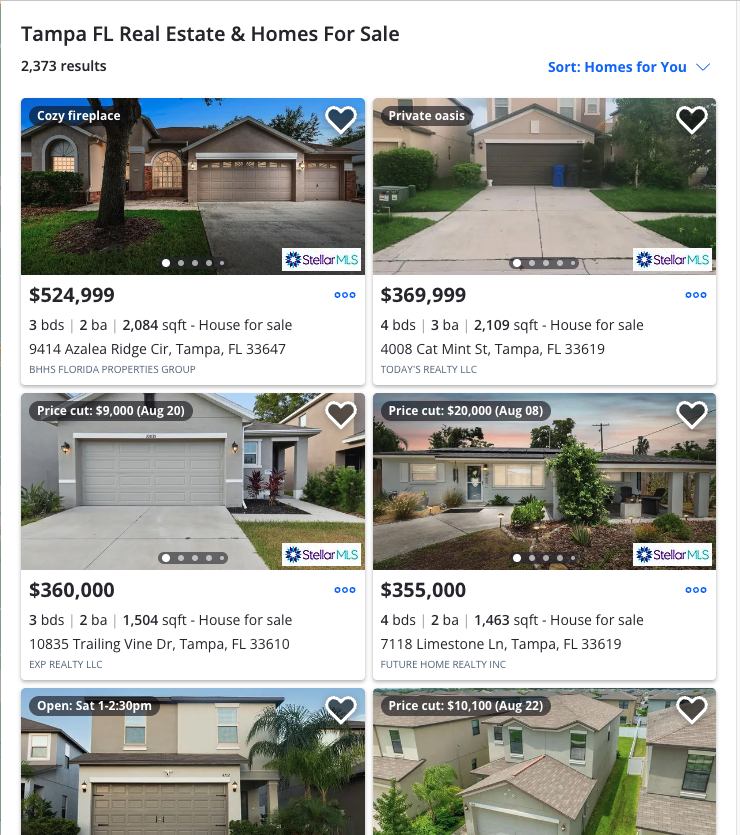
To open the developer tools in your browser, click on the three dots at the rightmost corner. Select “More Tools,” then “Developer Tools.” This will give you access to the web page’s source code.
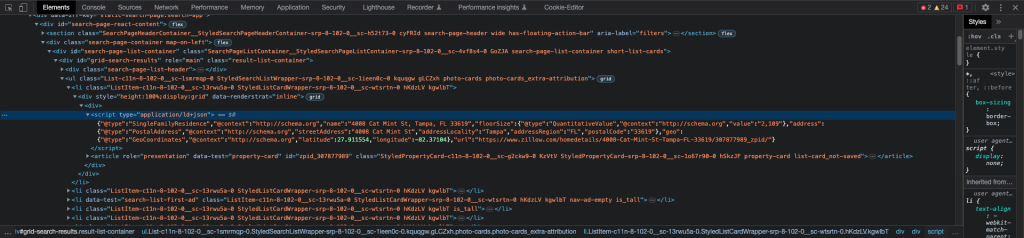
Hover around one of the cards in the above properties, right-click, and select “Inspect Element.” This will show you exactly where the building blocks of those elements are present. As shown in the figure, you will find data in JSON format, specifically in the <script> (script) tag, with type=”application/ld+json.”
Now we have the data source ready to be scraped for one property! These scripts are inside the <li> (list) tags.
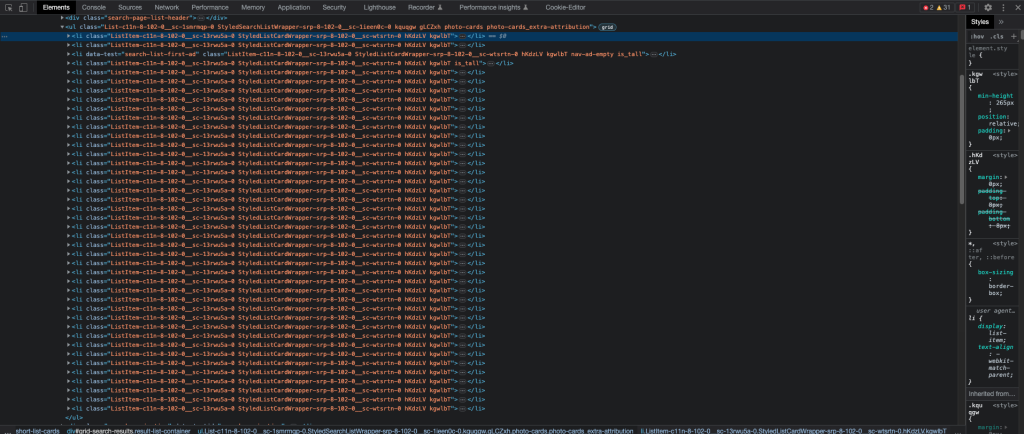
Zooming out, some tags listed may contain JSON data that possess valuable information about the properties.
Now that we’ve found the data source, we need to automate the scraping. To do so, we’ll use Selenium. Selenium is a powerful web automation toolkit for automating web application testing, scraping, and much more.
First, we’ll import some necessary packages required for Selenium to work, as well as some utilities that we’ll need:

Powered by - Wemake