file_path = 'amz_data.csv'
def extract_info_to_dataframe(url, proxies):
# Get page content
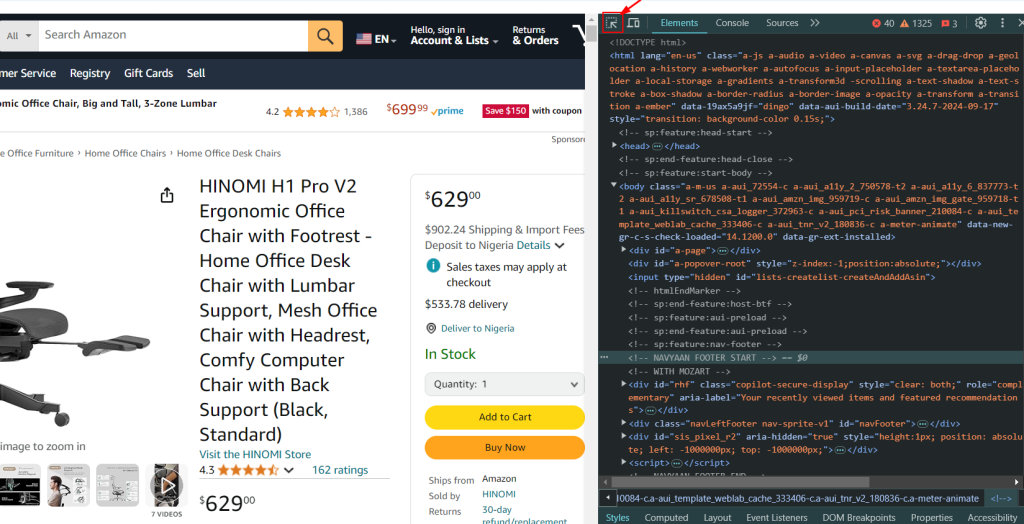
soup = get_page_content(url, proxies)
# Extract product information
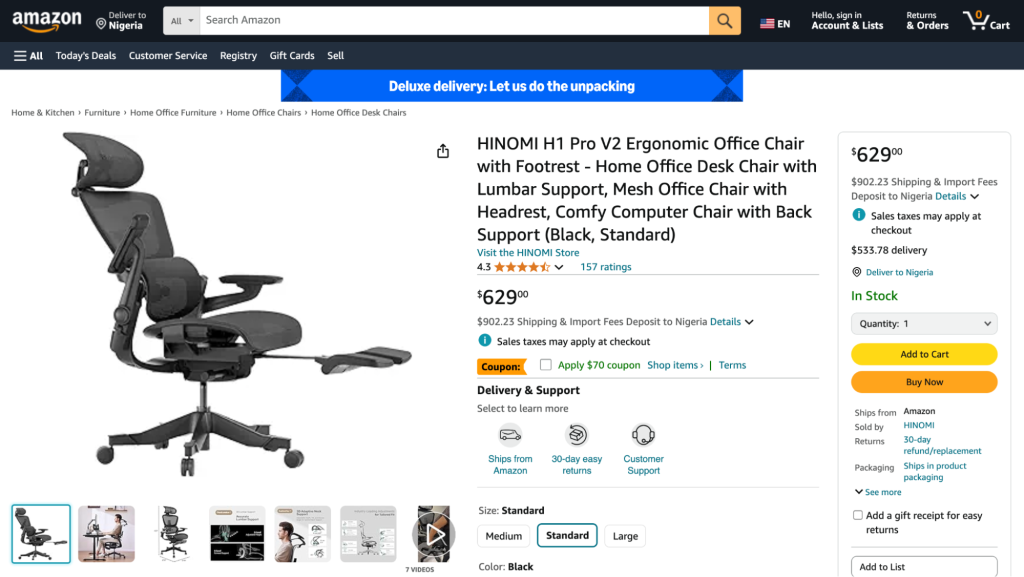
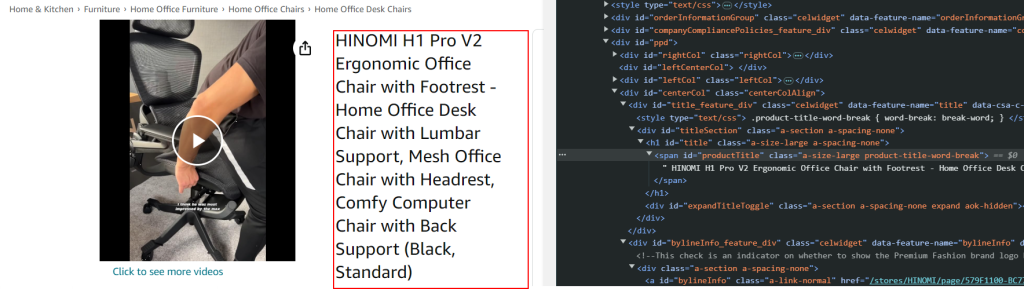
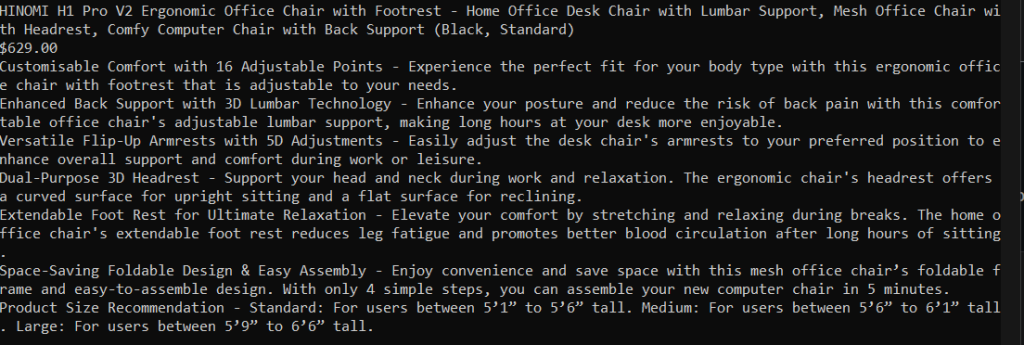
title, price, description = get_product_information(soup)
product_info = [
{"Title": title,
"Price": price,
"Description": description}]
# Extract similar products
similar_products = []
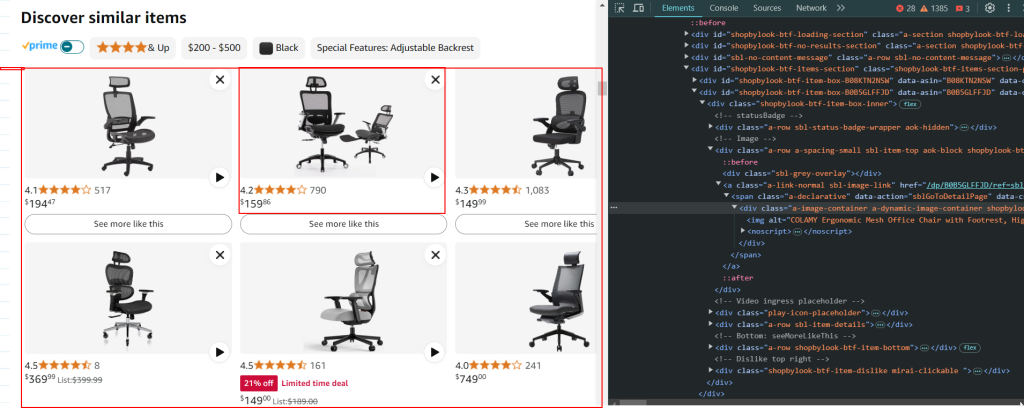
items_section = soup.find_all('div', class_='shopbylook-btf-item-box')
if not items_section:
print("No items found with the class 'shopbylook-btf-item-box'.")
else:
for item in items_section:
product_title, final_price = get_similar_products(item)
similar_products.append({
"Similar Product Title": product_title,
"Similar Product Price": final_price})
# Extract reviews
review_details = []
#Extract reviews from users in countries outside USA
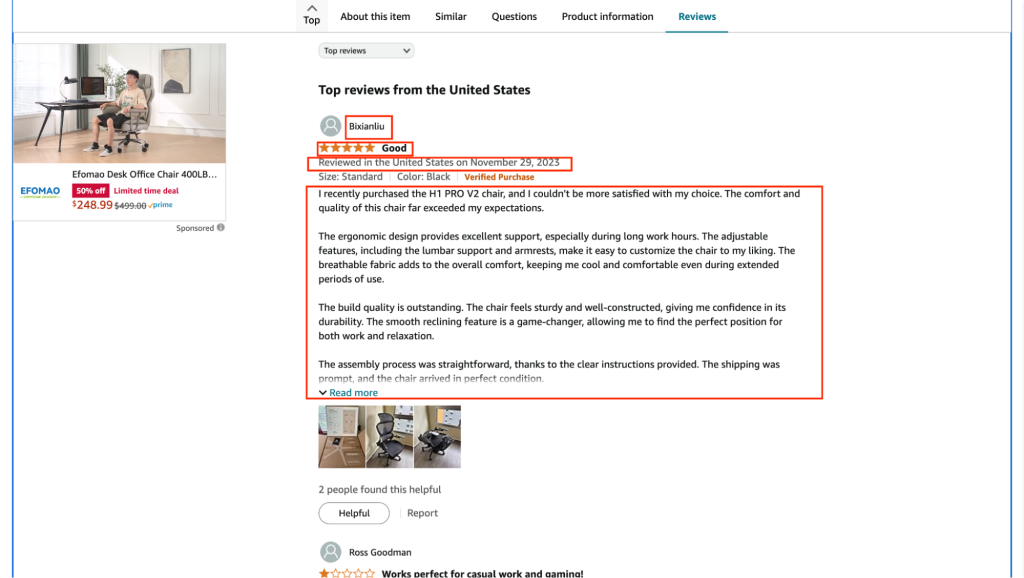
foreign_reviews = soup.find_all('div', class_='a-section review aok-relative cr-desktop-review-page-0')
for review in foreign_reviews:
name, country, rating, review_text = get_review_details(review)
review_details.append({
"Reviewer Name": name,
"Location": country,
"Rating": rating,
"Review Text": review_text
})
#Extract reviews from users in countries outside USA
us_reviews = soup.find_all('div', attrs={'data-hook': 'review', 'class': 'a-section review aok-relative'})
for review in us_reviews:
name, country, rating, review_text = get_review_details(review)
review_details.append({
"Reviewer Name": name,
"Location": country,
"Rating": rating,
"Review Text": review_text
})
# Prepare the product information for DataFrame
# for product_title, final_price in similar_products:
h = pd.DataFrame.from_dict(product_info)
#convert the list to a pandas series
i = pd.Series(similar_products)
#convert the list to a pandas series
j = pd.Series(review_details)
#this results in a dataframe with a column containing the dictionaries
#similar_products_title and similar_products_name in one column under 0
# and the dictionaries in review_data in one column named 1
df = pd.concat([h,i,j], axis = 1)
# Extract the two columns from the dictionaries in column "0"
sp = pd.json_normalize(df[0])
# Rename the columns as needed
sp.columns = ['Similar Products Title', 'Similar Products Price']
# Extract the two columns from the dictionaries in column "1"
rp = pd.json_normalize(df[1])
# Rename the columns as needed
rp.columns = ['Reviewer Name', 'Rating', 'Location', 'Review Text']
# Concatenate the new columns with the original DataFrame
df = pd.concat([df, sp], axis=1)
df = pd.concat([df, rp], axis=1)
#Drop the unwanted columns
df.drop(columns=[0,1], inplace=True)
# df = pd.DataFrame.from_dict(merged_list)
if os.path.exists(file_path):
# If it exists, delete it
os.remove(file_path)
# Save the new dataframe (it will overwrite if the file existed)
df.to_csv(file_path, index=False)
# Create a DataFrame from the collected data
pass
if __name__ == "__main__":
extract_info_to_dataframe(url, proxies)