import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
# Sample proxy (replace with your own proxy details)
proxy = {
"http": "http://username:password@host:port",
"https": "http://username:password@host:port"
}
# Headers to mimic a real browser request
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"Connection": "keep-alive",
"DNT": "1"
}
# Sample dataset of 10 products with their URLs (mocked for demonstration)
products = [
{"name": "Hanes Breathable ComfortFlex", "url": "https://www.amazon.com/Hanes-Breathable-ComfortFlex-Waistband-Multipack/dp/B086KSDTQ4/"},
{"name": "PreserVision AREDS Supplement", "url": "https://www.amazon.com/PreserVision-AREDS-Vitamin-Mineral-Supplement/dp/B00DJUK8HS/"},
{"name": "Nature's Bounty Probiotics", "url": "https://www.amazon.com/Natures-Bounty-Probiotics-Supplement-Acidophilus/dp/B004JO3JTM/"},
{"name": "AmazonBasics Batteries", "url": "https://www.amazon.com/AmazonBasics-Performance-Alkaline-Batteries-Count/dp/B00MNV8E0C/"},
{"name": "Tree of Life Hyaluronic Acid", "url": "https://www.amazon.com/Tree-Life-Hyaluronic-Brightening-Hydrating/dp/B014PGEEO2/"},
{"name": "Massage Gun", "url": "https://www.amazon.com/Massage-Tissue-Percussion-Massager-Athletes/dp/B09JBCSC7H/"},
{"name": "Fruit of the Loom Briefs", "url": "https://www.amazon.com/Fruit-Loom-Brief-12-Pack-Assorted-Heathers/dp/B086Z331TY/"},
{"name": "Probiotics Supplement", "url": "https://www.amazon.com/Probiotics-Formulated-Probiotic-Supplement-Acidophilus/dp/B079H53D2B/"},
{"name": "Duracell CopperTop Batteries", "url": "https://www.amazon.com/Duracell-CopperTop-Batteries-All-Purpose-Household/dp/B004K95PBQ/"},
{"name": "Gloria Vanderbilt Jeans", "url": "https://www.amazon.com/Gloria-Vanderbilt-Classic-Tapered-Scottsdale/dp/B01KO2GU3Y/"},
]
# Function to get product page via proxy
def get_product_page(url):
try:
response = requests.get(url, proxies=proxy, headers=headers)
response.raise_for_status()
return response.text
except Exception as e:
print(f"Failed to fetch product page: {e}")
return None
# Function to simulate fetching Amazon product price from HTML using BeautifulSoup
def parse_amazon_price(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
# Simulate finding the product price (mock for demo purposes)
price_tag = soup.find('span', {'class': 'a-price-whole'})
if price_tag:
return float(price_tag.get_text(strip=True).replace(',', ''))
# Mock return if parsing fails (simulating real prices)
return round(random.uniform(50, 600), 2)
# Function to simulate price fluctuations
def simulate_price_change(current_price):
change = random.uniform(-0.1, 0.1) * current_price # price changes between -10% to +10%
return round(current_price + change, 2)
# Log price changes over 14 days
days = 14
price_data = {product['name']: [100.0] for product in products} # Start with a mocked initial price of $100
for day in range(1, days + 1):
for product in products:
new_price = simulate_price_change(price_data<div class="woocommerce "><ul class="products columns-4">
<div class="col-12 col-lg-4">
<div class="product type-product post-78863 status-publish first instock product_cat-uncategorized has-post-thumbnail shipping-taxable purchasable product-type-variable-subscription has-default-attributes">
<div class="card">
<div class="card-body">
<a href="https://thesocialproxy.com/product/137557-managed-pool/" class="woocommerce-LoopProduct-link woocommerce-loop-product__link"><p class="mt-4"><img decoding="async" src="data:image/svg+xml,%3Csvg%20xmlns=&#039;http://www.w3.org/2000/svg&#039;%20width=&#039;0&#039;%20height=&#039;0&#039;%20viewBox=&#039;0%200%200%200&#039;%3E%3C/svg%3E" alt="#137557 - Managed Pool" class="img-fluid perfmatters-lazy" data-src="https://thesocialproxy.com/wp-content/uploads/2020/08/dongle-blue-3.svg" /><noscript><img decoding="async" src="https://thesocialproxy.com/wp-content/uploads/2020/08/dongle-blue-3.svg" alt="#137557 - Managed Pool" class="img-fluid" /></noscript></p><h2 class="woocommerce-loop-product__title"><a class="woocommerce-LoopProduct-link woocommerce-loop-product__link" href="https://thesocialproxy.com/product/137557-managed-pool/">#137557 &#8211; Managed Pool </a></h2>
<span class="price"><span class='yay-currency-cache-product-id' data-yay_currency-product-id='78863'><span class="woocommerce-Price-amount amount">
<span class="woocommerce-Price-currencySymbol">€</span></span></span></span>
</a> <!-- Features -->
<div class="mb-md-5 mb-3">
<ul class="list-group list-group-flush ml-0">
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Multi-location license*</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Private & unlimited connection</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Multiple carriers</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>IP rotation enabled</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>API enabled</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Same IP used by real users</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Highest IP trust score</small> <i class="fe fe-check-circle text-success"></i>
</li>
</ul>
</div>
<a href="https://thesocialproxy.com/product/137557-managed-pool/" aria-describedby="woocommerce_loop_add_to_cart_link_describedby_78863" data-quantity="1" class="button product_type_variable-subscription add_to_cart_button" data-product_id="78863" data-product_sku="" aria-label="Select options for &ldquo;#137557 - Managed Pool&rdquo;" rel="nofollow">Select options</a> <span id="woocommerce_loop_add_to_cart_link_describedby_78863" class="screen-reader-text">
This product has multiple variants. The options may be chosen on the product page </span>
</div>
</div>
</div>
</div>
</ul>
</div>][-1])
price_data<div class="woocommerce "><ul class="products columns-4">
<div class="col-12 col-lg-4">
<div class="product type-product post-78863 status-publish first instock product_cat-uncategorized has-post-thumbnail shipping-taxable purchasable product-type-variable-subscription has-default-attributes">
<div class="card">
<div class="card-body">
<a href="https://thesocialproxy.com/product/137557-managed-pool/" class="woocommerce-LoopProduct-link woocommerce-loop-product__link"><p class="mt-4"><img decoding="async" src="data:image/svg+xml,%3Csvg%20xmlns=&#039;http://www.w3.org/2000/svg&#039;%20width=&#039;0&#039;%20height=&#039;0&#039;%20viewBox=&#039;0%200%200%200&#039;%3E%3C/svg%3E" alt="#137557 - Managed Pool" class="img-fluid perfmatters-lazy" data-src="https://thesocialproxy.com/wp-content/uploads/2020/08/dongle-blue-3.svg" /><noscript><img decoding="async" src="https://thesocialproxy.com/wp-content/uploads/2020/08/dongle-blue-3.svg" alt="#137557 - Managed Pool" class="img-fluid" /></noscript></p><h2 class="woocommerce-loop-product__title"><a class="woocommerce-LoopProduct-link woocommerce-loop-product__link" href="https://thesocialproxy.com/product/137557-managed-pool/">#137557 &#8211; Managed Pool </a></h2>
<span class="price"><span class='yay-currency-cache-product-id' data-yay_currency-product-id='78863'><span class="woocommerce-Price-amount amount">
<span class="woocommerce-Price-currencySymbol">€</span></span></span></span>
</a> <!-- Features -->
<div class="mb-md-5 mb-3">
<ul class="list-group list-group-flush ml-0">
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Multi-location license*</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Private & unlimited connection</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Multiple carriers</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>IP rotation enabled</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>API enabled</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Same IP used by real users</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Highest IP trust score</small> <i class="fe fe-check-circle text-success"></i>
</li>
</ul>
</div>
<a href="https://thesocialproxy.com/product/137557-managed-pool/" aria-describedby="woocommerce_loop_add_to_cart_link_describedby_78863" data-quantity="1" class="button product_type_variable-subscription add_to_cart_button" data-product_id="78863" data-product_sku="" aria-label="Select options for &ldquo;#137557 - Managed Pool&rdquo;" rel="nofollow">Select options</a> <span id="woocommerce_loop_add_to_cart_link_describedby_78863" class="screen-reader-text">
This product has multiple variants. The options may be chosen on the product page </span>
</div>
</div>
</div>
</div>
</ul>
</div>].append(new_price)
# Convert to DataFrame for easier plotting
price_df = pd.DataFrame(price_data)
price_df['Day'] = np.arange(0, days + 1)
# Plotting the price changes
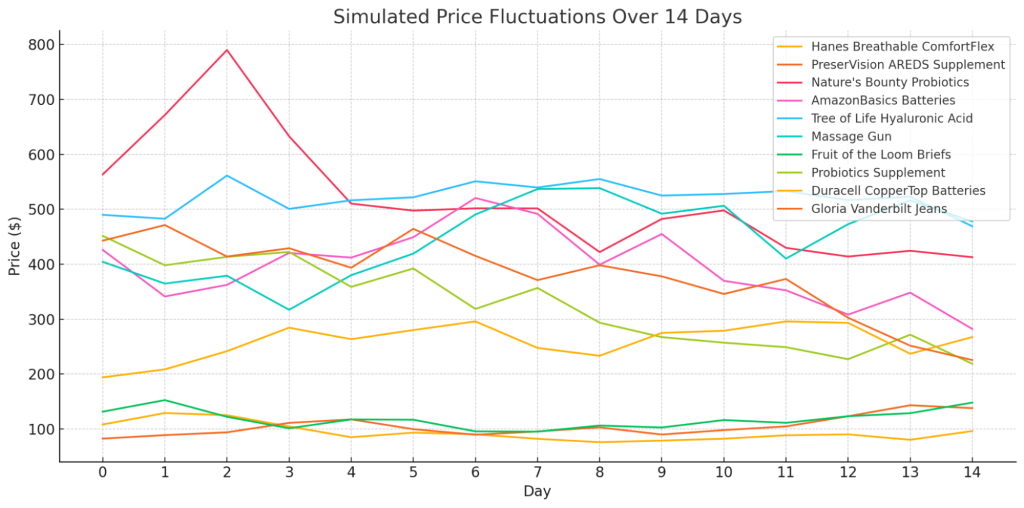
def plot_price_changes(df):
plt.figure(figsize=(10, 6))
for product in df.columns[:-1]: # Exclude 'Day'
plt.plot(df['Day'], df, label=product)
plt.title('Price Fluctuations Over 14 Days')
plt.xlabel('Day')
plt.ylabel('Price')
plt.legend(loc='upper right')
plt.grid(True)
plt.show()
# Generate the graph showing price changes
plot_price_changes(price_df)
# Simulating a forced price drop and showing the alert mechanism
def send_email_alert(product_name, initial_price, current_price, url):
# Mock sending an email alert
print(f"ALERT: {product_name} has dropped from ${initial_price:.2f} to ${current_price:.2f}. Check it here: {url}")
# Check for price drops and trigger alerts
def check_for_price_drops(df):
for product in products:
initial_price = df<div class="woocommerce "><ul class="products columns-4">
<div class="col-12 col-lg-4">
<div class="product type-product post-78863 status-publish first instock product_cat-uncategorized has-post-thumbnail shipping-taxable purchasable product-type-variable-subscription has-default-attributes">
<div class="card">
<div class="card-body">
<a href="https://thesocialproxy.com/product/137557-managed-pool/" class="woocommerce-LoopProduct-link woocommerce-loop-product__link"><p class="mt-4"><img decoding="async" src="data:image/svg+xml,%3Csvg%20xmlns=&#039;http://www.w3.org/2000/svg&#039;%20width=&#039;0&#039;%20height=&#039;0&#039;%20viewBox=&#039;0%200%200%200&#039;%3E%3C/svg%3E" alt="#137557 - Managed Pool" class="img-fluid perfmatters-lazy" data-src="https://thesocialproxy.com/wp-content/uploads/2020/08/dongle-blue-3.svg" /><noscript><img decoding="async" src="https://thesocialproxy.com/wp-content/uploads/2020/08/dongle-blue-3.svg" alt="#137557 - Managed Pool" class="img-fluid" /></noscript></p><h2 class="woocommerce-loop-product__title"><a class="woocommerce-LoopProduct-link woocommerce-loop-product__link" href="https://thesocialproxy.com/product/137557-managed-pool/">#137557 &#8211; Managed Pool </a></h2>
<span class="price"><span class='yay-currency-cache-product-id' data-yay_currency-product-id='78863'><span class="woocommerce-Price-amount amount">
<span class="woocommerce-Price-currencySymbol">€</span></span></span></span>
</a> <!-- Features -->
<div class="mb-md-5 mb-3">
<ul class="list-group list-group-flush ml-0">
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Multi-location license*</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Private & unlimited connection</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Multiple carriers</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>IP rotation enabled</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>API enabled</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Same IP used by real users</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Highest IP trust score</small> <i class="fe fe-check-circle text-success"></i>
</li>
</ul>
</div>
<a href="https://thesocialproxy.com/product/137557-managed-pool/" aria-describedby="woocommerce_loop_add_to_cart_link_describedby_78863" data-quantity="1" class="button product_type_variable-subscription add_to_cart_button" data-product_id="78863" data-product_sku="" aria-label="Select options for &ldquo;#137557 - Managed Pool&rdquo;" rel="nofollow">Select options</a> <span id="woocommerce_loop_add_to_cart_link_describedby_78863" class="screen-reader-text">
This product has multiple variants. The options may be chosen on the product page </span>
</div>
</div>
</div>
</div>
</ul>
</div>][0]
current_price = df<div class="woocommerce "><ul class="products columns-4">
<div class="col-12 col-lg-4">
<div class="product type-product post-78863 status-publish first instock product_cat-uncategorized has-post-thumbnail shipping-taxable purchasable product-type-variable-subscription has-default-attributes">
<div class="card">
<div class="card-body">
<a href="https://thesocialproxy.com/product/137557-managed-pool/" class="woocommerce-LoopProduct-link woocommerce-loop-product__link"><p class="mt-4"><img decoding="async" src="data:image/svg+xml,%3Csvg%20xmlns=&#039;http://www.w3.org/2000/svg&#039;%20width=&#039;0&#039;%20height=&#039;0&#039;%20viewBox=&#039;0%200%200%200&#039;%3E%3C/svg%3E" alt="#137557 - Managed Pool" class="img-fluid perfmatters-lazy" data-src="https://thesocialproxy.com/wp-content/uploads/2020/08/dongle-blue-3.svg" /><noscript><img decoding="async" src="https://thesocialproxy.com/wp-content/uploads/2020/08/dongle-blue-3.svg" alt="#137557 - Managed Pool" class="img-fluid" /></noscript></p><h2 class="woocommerce-loop-product__title"><a class="woocommerce-LoopProduct-link woocommerce-loop-product__link" href="https://thesocialproxy.com/product/137557-managed-pool/">#137557 &#8211; Managed Pool </a></h2>
<span class="price"><span class='yay-currency-cache-product-id' data-yay_currency-product-id='78863'><span class="woocommerce-Price-amount amount">
<span class="woocommerce-Price-currencySymbol">€</span></span></span></span>
</a> <!-- Features -->
<div class="mb-md-5 mb-3">
<ul class="list-group list-group-flush ml-0">
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Multi-location license*</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Private & unlimited connection</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Multiple carriers</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>IP rotation enabled</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>API enabled</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Same IP used by real users</small> <i class="fe fe-check-circle text-success"></i>
</li>
<li class="list-group-item d-flex align-items-center justify-content-between px-0">
<small>Highest IP trust score</small> <i class="fe fe-check-circle text-success"></i>
</li>
</ul>
</div>
<a href="https://thesocialproxy.com/product/137557-managed-pool/" aria-describedby="woocommerce_loop_add_to_cart_link_describedby_78863" data-quantity="1" class="button product_type_variable-subscription add_to_cart_button" data-product_id="78863" data-product_sku="" aria-label="Select options for &ldquo;#137557 - Managed Pool&rdquo;" rel="nofollow">Select options</a> <span id="woocommerce_loop_add_to_cart_link_describedby_78863" class="screen-reader-text">
This product has multiple variants. The options may be chosen on the product page </span>
</div>
</div>
</div>
</div>
</ul>
</div>].iloc[-1] # Get latest price (14th day)
# Calculate percentage drop
price_drop_percentage = ((initial_price - current_price) / initial_price) * 100
# If price dropped by 20% or more, trigger alert
if price_drop_percentage >= 20:
send_email_alert(product['name'], initial_price, current_price, product['url'])
# Re-run the check on day 14
check_for_price_drops(price_df)
# Force a price drop for one of the products for demonstration (if none occurs)
def force_price_drop(df):
product_to_drop = random.choice(df.columns[:-1]) # Select a random product
df.loc[days, product_to_drop] = df.loc[0, product_to_drop] * 0.75 # Simulate a 25% drop in price
# Force a price drop for demonstration
force_price_drop(price_df)
# Plot the forced price changes
plot_price_changes(price_df)
# Check for price drops again after forcing it
check_for_price_drops(price_df)