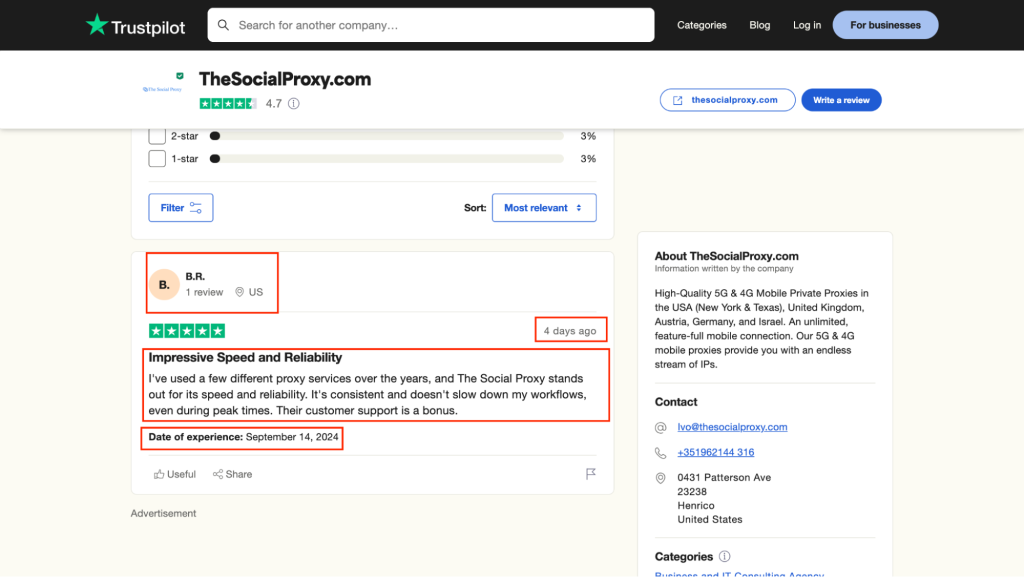
3. Click “Filter” to filter reviews by star rating, date, popular mentions, location, etc.
4. To filter reviews by verified status or those with replies, select the review option.
After making your selection, you’ll see each review arranged in white boxes, listed by date. Important review data includes:
- Review text
- Reviewer name
- Reviewer location
- Date of experience
- Review post date