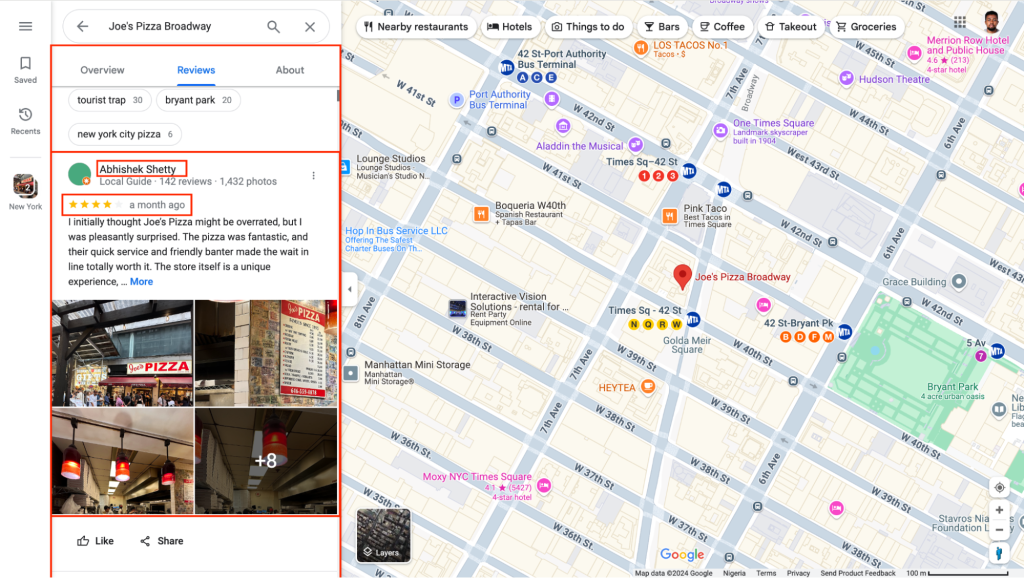
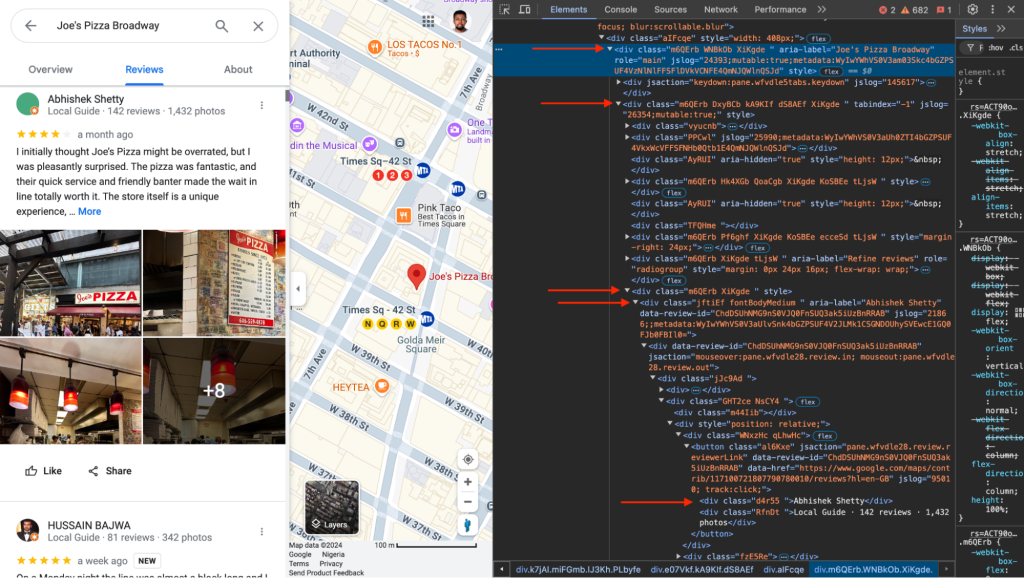
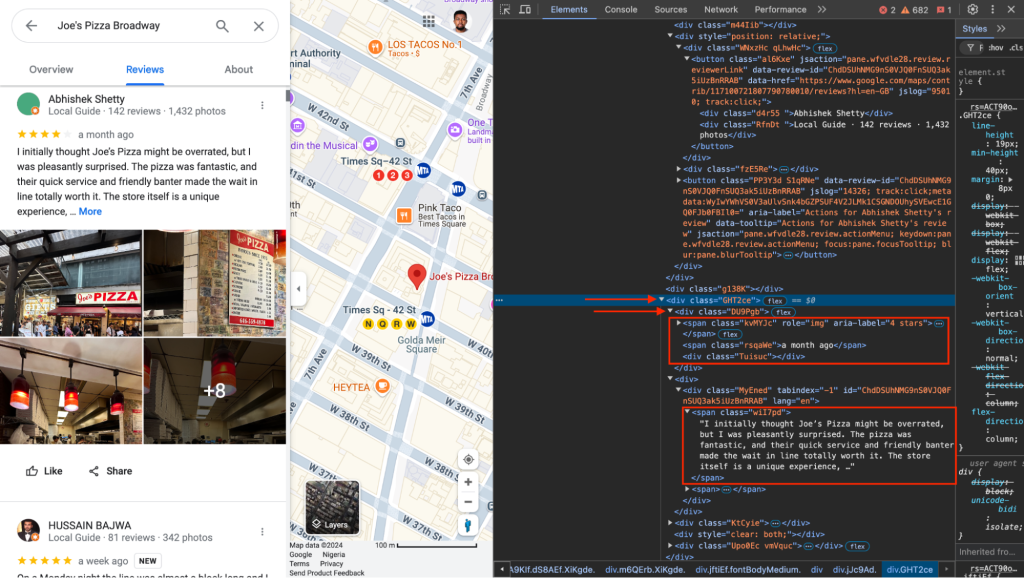
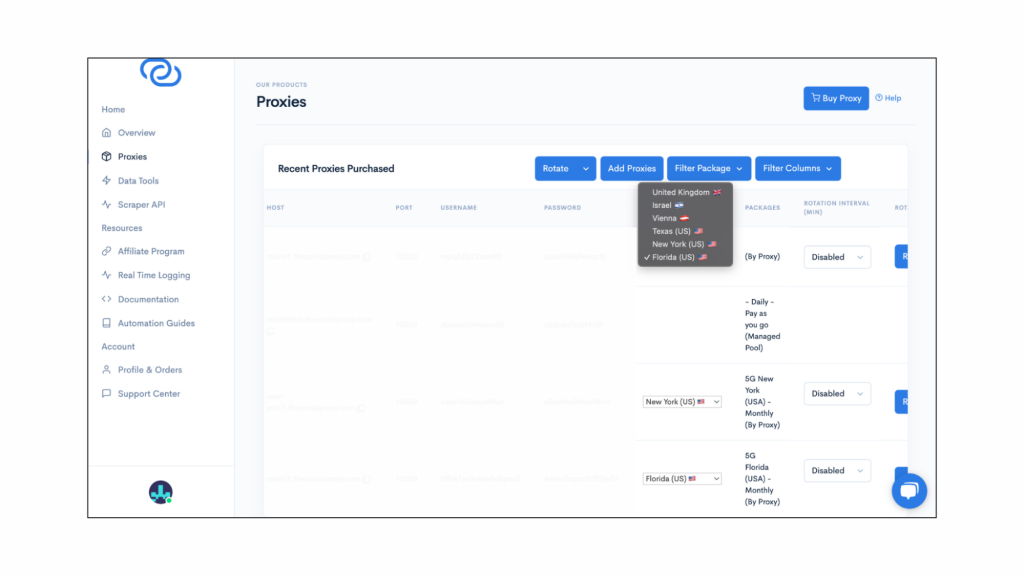
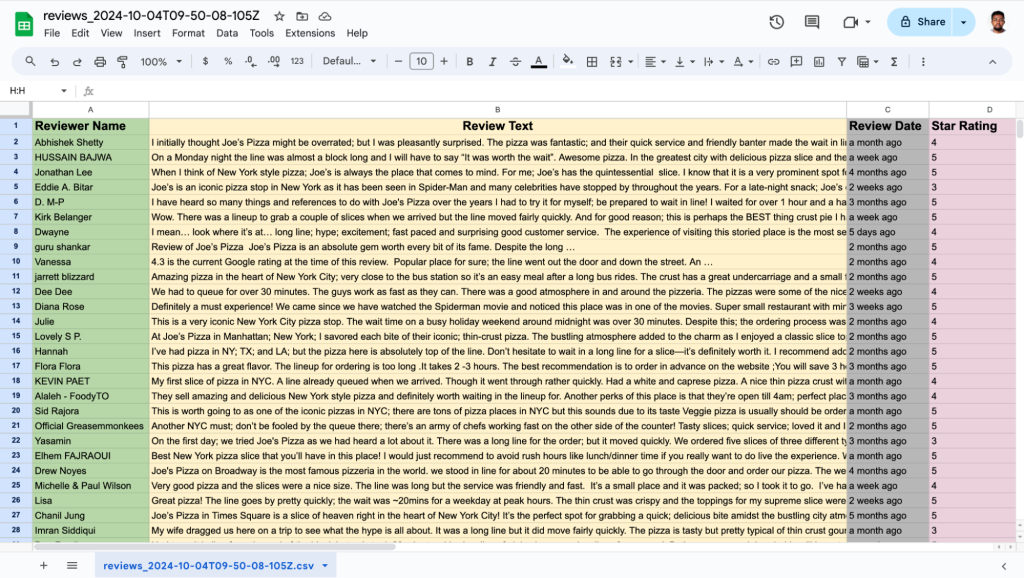
In this tutorial, we demonstrated how to scrape Google Business reviews from Google Maps for the keyword “Pizza in New York” using NodeJS, Puppeteer, and The Social Proxy’s mobile proxy to bypass Google’s anti-scraping mechanisms. You learned how to target essential HTML elements, such as review content, reviewer names, timestamps, and star ratings to extract valuable review data.
With the data you’ve collected, the possibilities for further exploration are endless. You can use the reviews to conduct market analysis, gauge customer sentiment, or identify gaps in competitor services. To go even further, consider extending your scraper to other regions or categories. The same techniques can be used to scrape reviews from any business type, whether it’s for restaurants, hotels, or other services across different cities and countries.